
End-to-End processes (process structure pt. 2)
After having a look at the functional business process view, we will have a look at a second process view in this article: the End-to-End (E2E) process view, which a lot of people are familiar with because this is how they experience their daily work. We will also have a look at the risk viewpoint, and how this can be incorporated/work with both process views.
End-to-End (E2E) business process view
A second process view that most clients build is the End-to-End view. These are processes that are assembled by processes from the functional decomposition (ideally variants of it, but we’ll discuss this later). These are typically easily identifiable because they follow a “From/To” naming structure like “Order to Cash”, “Procure to Pay”, or “Hire to Fire”. They are also defined by the start and end events, which are the bookmarks of the process, and typically these also can be used to define what is *not* included in the E2E process.
In addition to the start/end events one of the first things you typically look at when defining an E2E is what the outcome of the process is, and how you can measure the success of it (using Key Performance Indicators mapped to processes and assigned KPI models that decompose those).
The main use case for E2Es are system implementations or other transformation projects, and process improvement i nitiatives. Typically you see E2Es created in the Solution Design phase of the process/solution lifecycle.

To create an E2E a bit of imagination is needed, and the first question is where to start and where to end. When making this decision, having a clear charter is helpful for obvious reasons – may it be the implementation of a new software (“let’s update our SAP Finance module, it’ll be fun” – has nobody ever said), or an organizational change.
In both cases the E2E is describing the process part of a capability and you should also check with your capability map which capabilities/capability areas you are tackling with this process.
How to create an E2E process?
Creating an E2E process is a process in itself that includes not only your project team, but ideally other stakeholders and process owners as well. It also might be triggered by the needs of your project, so the PMO might be able to deliver information about the “why” and how the project is aligned to the company’s strategy.
- The good news is, that you have already defined process ownership, so the first step is to define the catalog of E2E processes, to make sure that there is an agreement not only which E2Es shall be created and where they start and end, but also which priority in a program they should have and which ones are to be created first.
- Then you should have a look at the performance indicators and how you will measure success. Creating a baseline (pun intended) and putting it on paper is a useful exercise for measuring the effectiveness of the E2E process and the improvement that the project is tasked to deliver later.
- Lastly the coordination of development (meetings, milestones, timelines) between the different teams should be determined, and which team will take the lead and which other teams need to collaborate and bring their requirements, so that all aspects of the E2E process are covered.
Sometimes this can evolve into a situation of negotiations like in a Turkish bazaar, and it is recommended to put the agreements onto paper (a release plan), so that everyone involved and new projects have a foundation to look at when requirements or timelines change. - After this overall agreement is reached, the modeling work can begin. The first activity here is to identify the functional processes on the last value-chain level (level 3 in our example, the “Business Processes“) and to determine if they are fully or just partially included in the E2E. In the graphic above these are highlighted in blue.
- Depending on your DB setup and structure that you have agreed on in your meta model, you might have to create higher-level models in the E2E Process View, as well, so that your E2E is on the same methodological level as the Business Processes in the Functional Process View.
- Then you can create the E2E model (value-chain) that includes variants of the Business Processes and have a consistent naming convention for those in place, like “Variant of name_of_business_process – context”. An example would be “Variant of Create Purchase Order – Material” [vs. Services that might be covered in another E2E]. Alternatively you can create an attribute that indicates that this object is a variant copy of the (functional) master object and a small graphic can be show at the symbol to indicate this.
I recommend to create swimlane diagrams for those in which each main process has its own lane (“Int 1” and “Int 2” in the graphic above) and you also create swimlanes for external participants.
Even though you might not model the content of those chevrons, you should include them so that it is clear what comes from whom, when process interfaces are defined (an example of an external process could be “Deliver material – vendor”). You also might think about adding an “external” boolean attribute, and have the external chevrons in a different color, so that they are easily identifiable. - For each variant chevron now create an assigned lower-level process model (BPMN or different notation as defined in your conventions), just as you would create any other model. Add all necessary information that is required, such as apps, data, risks, transaction codes, etc. You also want to have a conversation with the process owners and see if they have already identified and imported existing processes, which then should be reused as an accelerator.
Also model the process interfaces to the other variants in this specific E2E, and don’t worry about the functional view for now. However, make sure that your start and end events are specific enough, so that you can identify the process and avoid having a generic name like “Order created” (which order? A purchase order – and if so, for material or services? – or a task order?). - The last step now is to add the KPIs that were defined in the initial definition/planning steps, to either the level 3 E2E process and/or to the level 4 lower-level process. This information what and where to measure the KPIs will be invaluable for others who will build dashboards or do process analysis/mining on the process in the future.
How do I manage my ever growing E2Es?
Now that we have created an E2E model with its assigned lower-level processes, we are still not completely done. In larger projects you easily run into the situation that you have defined your E2Es too narrow or too wide, or you realize that other E2Es also cover a process that is part of your E2E.
For that reason a coordination is needed. Have a look at the graphic below that shows three E2Es that are related to each other.

- The dark blue End-to-End process can stand on its own. It has a clear start and end event and can be implemented.
- The gray E2E is a successor of the dark blue E2E process. So there needs to be a coordination with the dark blue E2E team that the process interfaces are well defined – what is the shared event? Is it specific enough? Does the gray E2E require another start event that should have been created in the blue E2E (which means it was not really ready for implementation and needs to be updated – either now or in a next iteration of the blue process)?
- We also see that the gray and the light blue E2E process share a L3 process (indicated in dark red). Now you have to check if they share steps in the L4 process or if they target only specific steps that are independent of each other. If they share the same steps, then an agreement on those is needed, or a plan for a future development needs to be put in place.
- There is also the possibility of having an E2E that is fully contained in one main process (onboarding, for example, might only happen within the HR main process), which can confuse your users and needs a special step in explaining why this is a fringe use case, and why you don’t want a “From/To” process name in your functional process view.
- If you already have a lower-level process in the functional view, then I recommend to create an attribute “Implementation Status” for these functions where you can select “in planning”, “in implementation”, and “implemented” and have them highlighted using your template, so that it is easily identifiable which steps of the functional process still need to be implemented when doing the next E2E planning exercise.
However, the only way to really manage all E2E processes is to plan their development in releases, and have a predictable schedule that not only avoids that someone misses that they should participate in conversations and decisions, but it also allows to communicate what is “up and coming” to your end users/viewers.
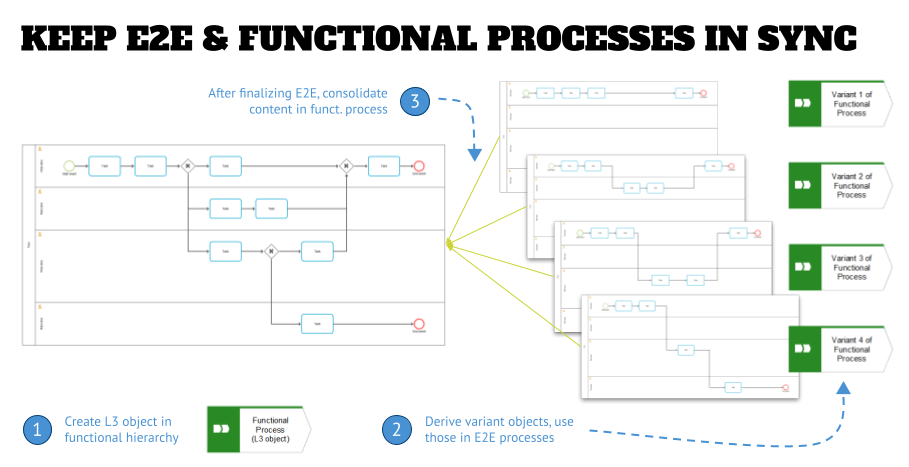
How do I keep both views in sync?
As indicated above, it is crucial that you do not see the E2E view as a standalone process view. It is tied to the functional process view, and is reusing the objects on the lower level, and managing dependencies and variations by using variants on the value-chain level.
The graphic below shows the activities in a release as overview:

- Identification of a L3 process in the functional process view, represented by a chevron.
- Creation of variants of that object in the E2E process view and assembly of L3 E2Es using these variants. After that new lower-level models can be created that are assigned to the variant objects. These use occurrence copies of the L4 functional process (if one exists), and will be modeled as needed for the E2E process (gateways, process interfaces, etc.).
- Once the lower level E2Es are finalized and approved, the content of those can be copied into the L4 functional model (the left one in the graphic above) and it can be approved, versioned, and published. Keep in mind that you might have to adjust the model and adapt it, so that it fits into the lower level of your functional process view.
In my experience the coordination effort for the releases is minimal in the bigger scheme of things and well worth spending the time for coordination.
What are the benefits of E2E processes?
There are multiple benefits of having End-to-End process models:
- The E2Es describe the functional scope of a project (“what needs to be done”), for example, in a business blueprint design for a system implementation.
- They can also describe a capability and make it “real” for non-architect types of users. After a successful implementation of an E2E process the organization has gained a capability – it “can do things” in this configuration of process, apps, data, roles, etc.
- They also are the basis for process improvement efforts. The KPIs that are defined can be measured in either traditional process analysis methods, or using data driven analysis such as process mining.
Unfortunately, the KPIs that are delivered with reference content, such as the APQC Process Classification Framework, are aligned to the functional process structure and you will have to do some re-shuffling when aligning them to your E2E processes if you want to use them as an accelerator. - Lastly, E2E process models will complete the functional process view (the “big map”) that is needed to have an overview of “what runs” for analysis in the Enterprise Baseline.
But what about risks?
I have to admit that I worked in projects that were mostly driven by Governance, Risk & Controls (GRC) folks. Even though they can be a powerful ally – think about the amount of fines an organization has to pay if they are not in compliance, which can help making the business case for implementing a process management capability easy – but they also have a different “view of the world”. It is driven by looking not at how an organization performs, or how it can improve its processes, but with the lens of risk identification, avoidance, and mitigation.
This can lead to the prime focus of managing the risk inventory and aligning them to processes, independent on which level that process exists, or if they are even related in a way that makes sense for the business. They also might add processes because certain apps or data are used in them that are related to the same class of risks.
In the end, it might create a picture as shown in the graphic below, that does neither fit into the functional decomposition, nor into the E2E structure … both views visualizing and structuring how the business “works”.
In the project mentioned above, it even went so far that we created a “risk-oriented process view” that stood on its own, and combined processes based on risk-related criteria. One example was a high-level process of “Account creation”, which was on the one hand side not very specific, and on the other hand it did not distinguish that the creation of an account for a credit card might be something completely different than creating an account for a mortgage (or an IT account for online banking).
Needless to say that the org units who were not involved in standing up that initial structure, but were supposed to add their processes to it as “fast followers”, could not work with it because they didn’t recognize themselves in this structure. This brought the project close to a failure after the successful initial push of appeasing the GRC requirements.

But how do you treat the legitimate demands of the GRC folks in all three Lines of Defense (operational risk management, the risk system, and internal audit) then?
My suggestion is to treat this topic not as a separate view, but to make it a reporting exercise that will provide the necessary reports and dashboards for the GRC stakeholders. This can be done by tagging the steps where risks occur and then model which controls mitigate these risk and how they will be tested (and who does the management of risks, controls, and tests). This structure, including the attributes of risks and controls, such as type, frequency of testing, etc., can then be sent to a GRC tool which then can automatically create audit plans and other things that are needed to manage the GRC requirements.
An architecture tool should also support the creation/import of existing catalogs for higher–level laws and regulations, regulatory obligations and requirements, policies, risks, controls, etc. so that business users who create process models can pick from a list and don’t have to create their own objects that then would need to be reconciled “after the fact” by admins and GRC folks.
The tool should furthermore support this with scripts that help “pushing” higher-level risks to lower-level steps and to created the relationships between tasks and controls (and thereby reducing the amount of manual work). Other useful features would be predefined workflows, scheduled reports, and dashboards for the GRC stakeholders.
In general I would expect the risks and controls to show up in the functional view, and recommend to handle the development in the same ways as described above when we were talking about how to keep both process views in sync: If you have risk and controls already identified in your functional processes then you are good. However, you should invite GRC folks to your E2E process development sessions, and model their input as well, so that when it comes to the third sync step above, the new relationships between tasks and risks will make their way into the functional process view for future analysis and auditing.
Conclusion
Both process views go hand-in-hand with each other when it comes to defining and describing your business processes. Having just one of those is not sufficient when you set up a full architecture in your tool. They will also help when it comes to coordination with the risk folks in your organization, which can be – depending on your relationship with them – your biggest friend or foe 🙂
Roland Woldt is a well-rounded executive with 25+ years of Business Transformation consulting and software development/system implementation experience, in addition to leadership positions within the German Armed Forces (11 years).
He has worked as Team Lead, Engagement/Program Manager, and Enterprise/Solution Architect for many projects. Within these projects, he was responsible for the full project life cycle, from shaping a solution and selling it, to setting up a methodological approach through design, implementation, and testing, up to the rollout of solutions.
In addition to this, Roland has managed consulting offerings during their lifecycle from the definition, delivery to update, and had revenue responsibility for them.
Roland has had many roles: VP of Global Consulting at iGrafx, Head of Software AG’s Global Process Mining CoE, Director in KPMG’s Advisory (running the EA offering for the US firm), and other leadership positions at Software AG/IDS Scheer and Accenture. Before that, he served as an active-duty and reserve officer in the German Armed Forces.