Architecture database setup and structure
Setting up your architecture database structure and the internal structure of an individual database is a task that is done very early in an implementation (and you are using a database-driven architecture tool, aren’t you?). It is defined in the “Technical Governance” phase, and typically is seen as an afterthought, even though it has a large impact on how easy your users will perceives and use the tool.
Let’s have a closer look at what needs to be thought of when designing your database structure and overall setup.
Use cases
The first thing you should think about it are the objectives and processes that you want to support with your architecture database setup (and to be very clear, we are talking about logical databases, and not the physical database where your tool stores all information). Some of the most use cases are:
- Release management
- Solution architecture and design
- Import of existing content
- Provisioning of Reference Content
- Archiving models for later use
- Synchronization with implementation and runtime systems
Typical architecture database setup
Even though you could setup your architecture program with just one database -and the newer tools support this, and got rid of separate publishing servers- it is recommended to have a multi-DB setup that allows you to set up a proper release cycle, and automate all activities in that process as well. More details on the topic of release management will be covered in another article.
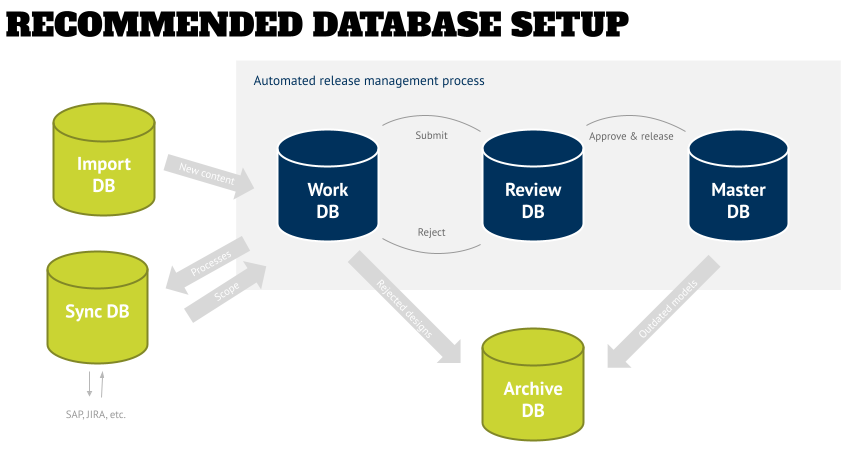
The graphic below shows the minimum recommended setup in the gray box:
- A “Work DB” as the only place where changes are made. The expectation should be that any content might be different tomorrow, and that only admins and modelers have access to this DB. Once a modeler submits a model for approval it then will be moved into a Review DB.
- The “Review DB” is a temporary location that is only used for the single purpose of being the staging area for reviews and preparation for publishing (following the release plan). The users of this DB are the stakeholders who play a role in the approval process – this can be business users for content approval, SOX reviewers, and technical QA folks who make sure that all models adhere to the formal standards of the organization, so that all models allow for proper analysis and also have a consistent look-and-feel.
Depending on the approval or rejection, a submitted model will be either sent back into the Work DB for changes, or will be versioned and merged into the Master DB. After the approval of all models in the Review DB they can be deleted, so that the database is pristine again for the next release of models. - The “Master DB” is the place for all non-modeling users and consumers, who most likely will just need a “view” license. The content here is the “official architecture” of the organization in the form of an up-to-date Enterprise Baseline (see below), and can be used for reporting, training, regulatory and other purposes.

Besides this core DB setup I recommend to have additional databases as needed (green in the graphic above):
- An “Import DB” – when importing content into your architecture tool, it expects an identifier that it uses to manage all models, objects, and connections in the database. For obvious reasons existing content that you want to import from legacy files (Visio), or other systems (e.g., any other tool that exports *.bpmn files) don’t have this information, and also might import additional content that is not needed or contradictory to your organization’s standard.
This database will be used for the “raw” import of models, and some initial clean-up before only the desired content will be merged into the Work DB for further normalization and integration.
And just to be clear – if you export content from your Work DB, for example for translation, and want to re-import it into your workspace, then you don’t have to use the Import DB, because those export/import reports maintain the individual IDs and therefore the tool recognizes the content during import and updates it accordingly. This is the preferred way when creating interfaces between the various systems of record and your architecture tool. - A “Synchronization DB” – some architecture tools allow a bidirectional synchronization with implementation or runtime systems (e.g., SAP’s Solution Manager). The risk of a bidirectional sync directly with the Work DB is that someone could have changed the scope in the implementation tool, which would then trigger the deletion of an object definition in the Work DB, while that object might be used in other models as well. For obvious reasons this is an undesired behavior – it will create “holes” in other models that cannot be easily restored. The use of a Sync DB allows you to do a sync and compare the result with the content in your Work DB before you merge the sync result into the Work DB.
- An “Archive DB”, which will hold content that is not relevant anymore, but should be kept for future purposes. Example content can be projects that never made to completion, but might include things that might be picked up at a later point in time – for example, when the technology that was researched in a project has matured so that it is a feasible for use in an enterprise.
The main benefit of merging the content out of the Work and Master DBs is that reporting and analysis will not show false results due to the outdated content.
Please note that you do not have to archive models when you use the versioning functionality of your tool. This will make sure that a copy/previous version will be saved and the content will be overwritten as part of the release cycle process mentioned above. This allows you to compare your latest model with earlier versions in your tool and is preferred over manually moving models, even if your tool still allows you to compare models in different databases. - The last database(s) that I recommend are Reference Content DBs. Those are the content starting points that you have identified as accelerators for your projects, but might not have a place in your architecture yet (see the bullet “reference content” below).
Internal database structure
As mentioned in the Frameworks article, you might choose to follow a framework, method, or reference content. Typically these can be used to structure your databases consistently – some of them, such as the SCOR reference model, deliver content in a certain structure that you might want to follow, while others, such as APQC’s Process Classification Framework, bring not only a structure, but also related KPI definitions and provide benchmarks (for a fee).
Either way, if you start from scratch, or adapt the content structure of existing reference content, the first thing you might want to have a look at is what your overall database structure should be. Typically reference content just gives you a certain slice of an architecture, such as processes, but not a full architecture structure.
Once you have defined what you want to do with your database, the high-level folder structure is determined. Typically you will find two main folders in it: Enterprise Baseline and Projects/Solutions. These reflect the “what runs” in all architecture views, while the latter is the place to design the “what changes” (also in all architecture views). Just because of this it is beneficial to define the structure of the architecture views next, so that this sub-structure is identical in both main areas. That will allow you to move content from the “Projects/Solutions” area into the “Enterprise Baseline” are when a project goes live, and it saves you the “translation” of the content to match the receiving structure.
My recommendation is to look for industry standards to determine this overall structure – a good candidate for this might be TOGAF’s framework and Architecture Development Method, or the ARIS method, which was developed before the tool was created. Adapt the structure of the views and stick with them going forward – your users and viewers will learn this quickly and expect it when they look around in the database(s), so that new learning is not required just because a single project has a different preference.
In addition to this, new projects will be accelerated because they can copy content from Baseline and change it in the Projects area. It will also improve the overall data quality, because the Baseline content is approves, and the project team does not start from scratch (and might forget to identify/capture things).
The graphic below shows the application of this in a project example.

Once you have setup this main folder structure, you might want to create some more high-level folders:
- “Reference Content” as read-only in case you want your users to actively reuse content. This might sound like a good idea first, but it might lead to the copying of other content that might not be a 100% fit, which will clutter your project’s area, and might influence the analysis results. You might want to consider to have reference content being provides in a separate read-only database, and have your project teams work with an admin or power user to clearly define what you need, and have them merge it into your project space.
- “Import” – this is a temporary folder that is used when importing existing content from legacy formats, that need to be sorted out as part of the normalization activities after the “raw” import. A future article will talk about this in more detail.
- I do not recommend to create an “Archive” folder, but rather use an external database for this purpose. This will improve the analysis results that you will do in case the user started the report/query on the “wrong” folder.
In summary
Setting up your architecture databases and defining the internal structure has its benefits and gives your users guidance and stable expectations what to find where once they’ve learned way how you have setup your databases. This increases the adoption of your designs, and also enables a common perspective on how things are seen and measured. A release cycle process that includes the initial creation and update of existing models, as well as regular certifications, will keep your content fresh for your users.
Roland Woldt is a well-rounded executive with 25+ years of Business Transformation consulting and software development/system implementation experience, in addition to leadership positions within the German Armed Forces (11 years).
He has worked as Team Lead, Engagement/Program Manager, and Enterprise/Solution Architect for many projects. Within these projects, he was responsible for the full project life cycle, from shaping a solution and selling it, to setting up a methodological approach through design, implementation, and testing, up to the rollout of solutions.
In addition to this, Roland has managed consulting offerings during their lifecycle from the definition, delivery to update, and had revenue responsibility for them.
Roland is the VP of Global Consulting at iGrafx, and has worked as the Head of Software AG’s Global Process Mining CoE, as Director in KPMG’s Advisory, and had other leadership positions at Software AG/IDS Scheer and Accenture. Before that, he served as an active-duty and reserve officer in the German Armed Forces.